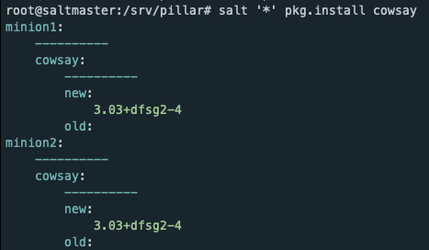
Pillar는 Salt Minion들이 어떠한 설정 값을 유지하기 원하는지 선언하기 때문에 Dynamic Variable보다는 Static Variable이 적용 되는 것이 Best
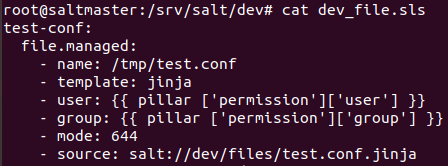
/srv/salt/dev/dev_files.sls
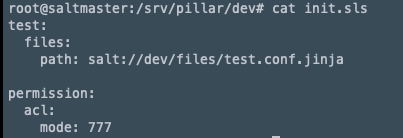
구성 파일로 해당 예제는 pillar에 선언된 대로 files/test.conf.jinja 파일을 정의하고 있다.
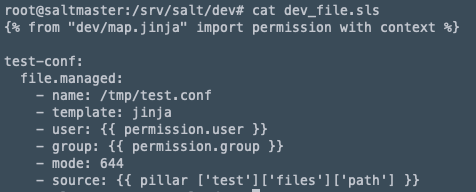
여기서 확인해야할 점은 첫 줄의 dev/map.jinja 파일로부터 permission의 context를 import하는 것으로 아래에 확인해보면 user와 group의 변수 확인시 permission.user 형식으로 지정되어 있다.
pillar나 grains를 통해 값을 가져오는것이 아닌 Mapping된 map.jinja 파일에서 값을 가져오는 것이다.
/srv/salt/dev/map.jinja
state.sls 파일에 변수 값을 넣을 경우 Minion 환경에 따라 다른 값이 들어가야하는 경우가 많다.
이런 경우 state.sls 파일에 모두 넣을 수 있지만 좋은 방법이 아니다.
state.sls 파일은 가독성이 좋도록 간단하게 작성하고 거기에 맵핑되는 변수들은 map.jinja 파일에 작성하는 것이 좋다. 물론 pillar에 넣어서 사용할 수도 있지만 pillar는 Dynamic Variable보다 Static Variable을 유지하는 것이 좋기 때문에 map.jinja 파일에 환경에 따른 Dynamic Variable을 지정하는 것이다.
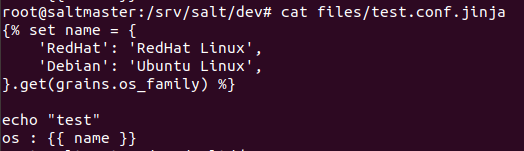
map.jinja 파일을 보면 dev_files.sls 파일에 들어가는 {{ permission.user }} 와 같은 변수가 정의되어 있다.
permission은 grains.filter_by의 리턴값에 따라 설정이 되는 기본적으로는 default를 사용하도록 되어 있는데 이것은 리턴된 값이 정의된 내용에 없는 경우에 사용한다.
리턴된 값이 정의된 내용에 있는 경우에는 state.sls 파일의 변수에 map.jinja의 내용들이 들어간다.
여기서 주의해야할점은 가장 아래 쪽에 있는 merge=salt'pillar.get', base='default' 이다.
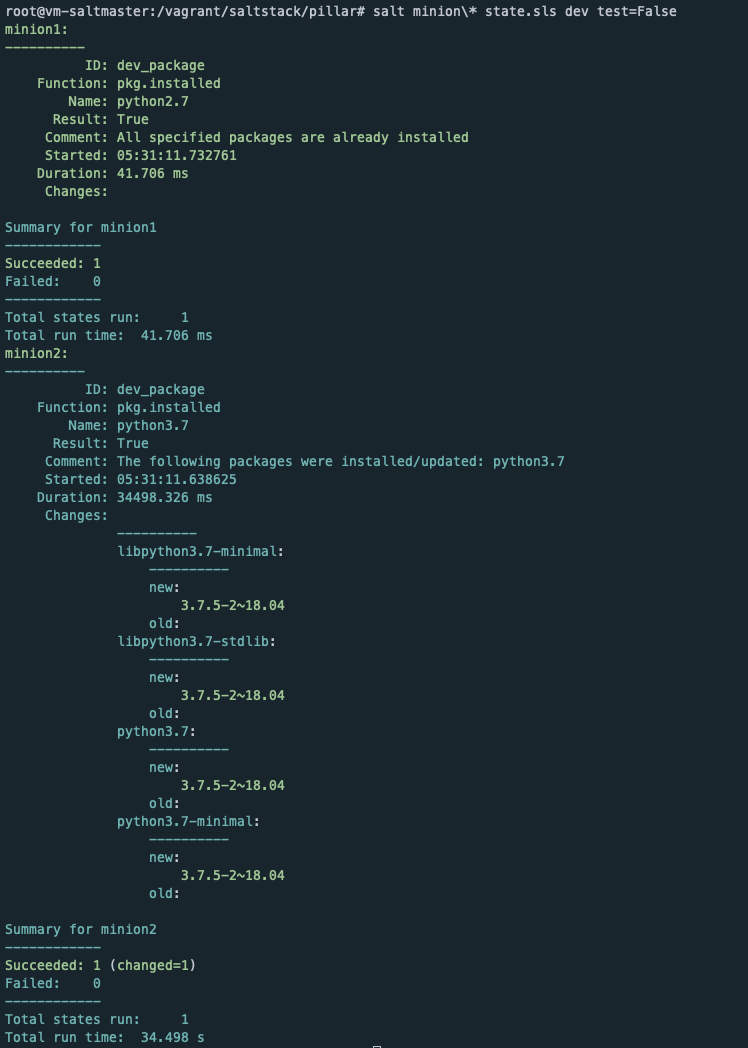
가장 위의 pillar 파일을 보면 permission의 mode 값이 777로 설정되어 있고 map.jinja에서는 644로 지정되어 있다.
merge 인수의 경우 가장 pillar의 값을 가져와 우선 적용 시킨다. 적용시 아래와 같다.
map.jinja에 mode가 644로 적용되어 있어도 pillar의 값인 777이 우선 적용되었다.
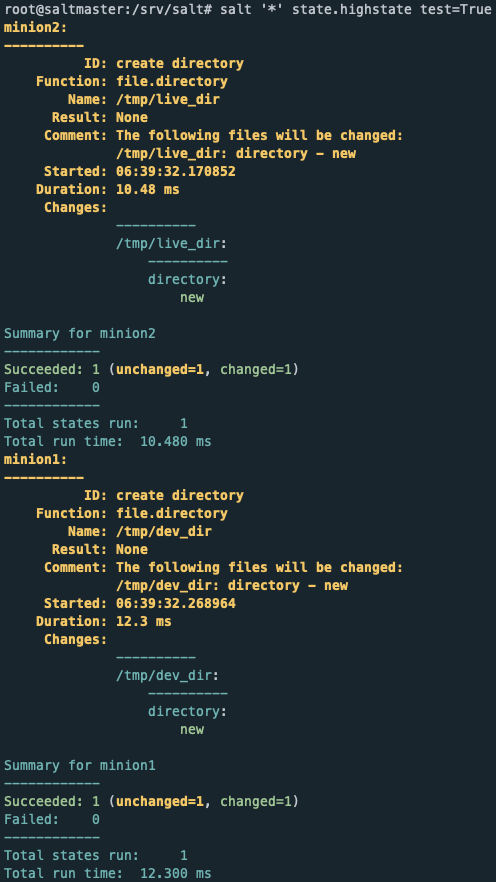
Slat Master ↔︎Salt Minion 간 통신에 사용되는 비동기 메시징 라이브러리
별도 설치 방식은 아니며 Slat Master를 설치하면 자동으로 함께 설치
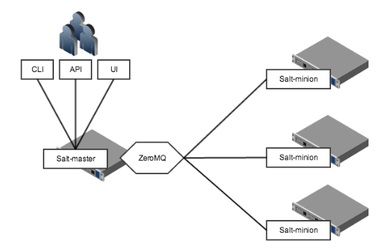
Publish Port : 4505 / Return Port : 4506 (Port 수정 가능)
Publish Port 4505
Publisher로서 모든 Salt Minion들이 명령을 받기 위해 해당 포트를 Listening
Master는 Minion의 4505 Port로 명령을 전달하며 모든 Minion은 비동기로 동시에 명령을 받아 수행
Return Port 4506
Minion들이 수행한 작업 결과를 받게되는 역할로 사용
결과 리턴뿐만 아니라 Minion이 Master에게 파일을 요청하거나 Minion의 특정 데이터 값 (Salt Pillar) 을 요청하는 Port로도 사용
4506 Port에 대한 연결은Master ↔︎Minion 간의 1:1 관계 (비동기 아님)
Salt SubSystem
Salt SubSystem이란 어떠한 역할을 하는 System으로 예를 들어 Command Interface라는 역할을 하는 SubSystem을 구축할 때 일반적으로 포함되는 Plug-Ins는 Python API, REST API, Command Line으로 이렇게 모인 Plug-In들이 하나의 SubSystem을 구성
아래는 기본 SubSystem
Authentication
작업을 실행하기 전에 사용자에게 권한을 부여
File Server
파일을 배포
Secure Data Store
사용자 정의 변수 및 기타 데이터를 안전하게 사용할 수 있음
State Representation
인프라 및 시스템 구성을 설명
Return Formatter
작업 결과를 표준화 된 데이터 구조로 형식화
Result Cache
작업 결과를 장기 저장소로 보냄
Remote Execution
소프트웨어 설치, 파일 및 시스템 관리에 필요한 기타 작업을 수행하는 다양한 작업을 실행
Configuration
원하는 상태와 일치하도록 대상 시스템을 구성
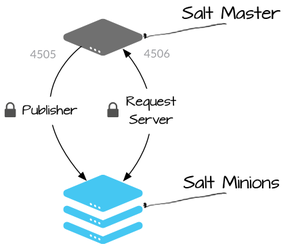
Salt SubSystem 구동 순서
명령 전달 (Master)
사용자 인증 (Master)
작업을 이벤트 버스에 배치하고 연결된 Minion에 전달 (Master)
작업 관리 구성 & 원격 작업 실행 (Master & Minion)
State 파일 다운로드 (Master) & 명령 실행 (Minion)
보안 데이터를 검색하여 상태 파일에 삽입 (Master)
상태 파일이 파싱되고 컴파일됨 (Minion)
상태가 적용되고 상태 모듈이 실행 (Minion)
결과는 형식화되어 이벤트 버스에 배치됨 (Master)
결과는 Long-Term 저장소로 전송됨
Reactors는 이벤트에 따라 트리거됨
각 단계에서 SubSystem은 작업을 구성된 Plug-In으로 위임함
각 단계에는 구성된 Plug-In에 따라 WorkFlow가 달라질 수 있음
Returner
Salt Returner는 Minion의 대한Remote Execution 결과가 전송되는 위치를 지정하는데 사용
기본적으로Minion → Master로 데이터를 반환하는데 Retuner는 Master가 아닌 다른 목적지로 전송하도록 Routing 할 수 있음
일반적으로 결과는 Returner와 Minion 명령을 시작한 프로세스에 지정된 대상으로 반환됨을 의미함
대부분의 Returner는 Database System이나 Metric 또는 Logging 서비스에 전달함
Returner는 작업 캐시, 이벤트 데이터와 같은 Salt의 특정 데이터를 수집하는데 사용될 수 있음
Reactors
Salt Reactors System은생성된 이벤트에 반응하여 동작을 트리거하는 매커니즘을 제공함
Salt에서는 인프라 전체에서 발생하는 변경 (Remote Execution & Runner) 으로 인해 Minion 또는 Master Daemon이 ZeroMQ Message Bus에 Event를 생성하는데 Reactors System은 이 Message Bus를 감시하고 적절한 대응을 하기위해 구성된 Reactor와 Event를 비교함
Reactors System의 주요 목표는 변경이 발생한 상항을 자동으로 생성하기위한 시스템을 제공하는 것(Event기반 Trigger 실행)
Salt 주의점
Salt Module 사용시 RedHat 계열 OS에 aptpkg Module을 사용하는 것처럼 맞지 않은 Module을 사용하면 Error Code 발생하니 환경에 맞는 Module을 사용해야함
Salt Security
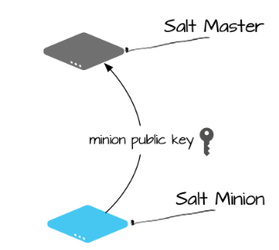
Salt Minion Auth
Minion은 처음 시작할 때 Network에서 이름이 Salt로 지정된 시스템을 검색함 (IP 또는 Hostname으로 변경 가능) → Vagarnt를 통해 구성을 쉽게 할 수 있음
시스템이 검색되면 Minion은 Network Handshake 과정 후 Public Key를 Master에게 전달
연결 후 Minion의 Public Key는 Master에 저장되며 salt-key 명령을 사용하여 Master에서 승인해야함 (해당 부분은 자동화된 매커니즘을 사용 가능→ Vagarnt등)
Master에서 Minion의 Public Key가 승인되지 않는다면 Salt가 ZeroMQ를 통한 Message를 보내도 Minion에서는 Public Key가 승인될때까지 명령을 실행하지 않음
Minion의 Public Key가 승인되면 Master는 Public Master Key와 전달하는 Message의 암호화 및 해독을 하는데 사용되는 AES Key를 반환하여 Minion에게 전달하며 반환되어 전달받은 Key는 해당 Minion만 해독 가능
Salt ACL
명령이 Minion에게 전달되기전 Salt는 ACL을 통해 명령 실행자의 권한이 있는지 확인
Salt Encryption
Master ↔︎Minion 간의 통신은 AES Key를 사용하여 암호화 & 복호화 방식으로 전달되며각 Minion 및 Session 마다 고유한 AES Key로 암호화됨 (Minion이 100개면 100개의 AES Key가 생성)
Salt Remote Execution
Salt 문법
Salt 기본 문법
Target
Taget이 '*'이면 모든 Minion에 전달
각 Minion은 명령을 검사하고 대상과 비교하여 평가하며 명령을 실행할지 여부를 결정
대상 시스템은 명령을 실행한 후 결과를 요청 서버로 리턴
Module.Function
위의 예제에서는 Module은 test이고 Function은 rand_sleep
test Module의 rand_sleep이라는 Function을 실행
Arguments
실행되는 Module.Function에 인자값을 부여
각 명령은 별도의 Worker 스레드로 분리되어 Minion은 여러 작업을 한번에 처리할 수 있음
Salt Module & Function
Salt는 원격 실행과 구성 관리 기능을 구분해서 제공하는데 원격 실행 기능은 실행 모듈을 통해 제공됨
이 Module은 Minion에 대한 작업을 수행하는 관련 Function들의 집합
Module
Module을 사용하면 시스템 (OS, Cloud, Container 등) 간의 차이점을 추상화할 수 있음
실제로 데이터를 수집하는 매커니즘이 서로 다른 Linux나 BSD를 사용하는 Minion에게서도 비슷한 정보를 얻을 수 있음
Salt는 즉시 사용가능한 기능을 제공하기 위해서 적절한 Module을 선택하여 제공함
Function
Module내에 포함되어 있는 Function으로 정의된 기능을 수행하는 역할
예를 들어 Command라는 Module내에는 ssh, pip 등과 같은 명령실행 Function이 포함되어 있음
Salt State System
Salt State System은 Remote Execution을 실행한 후 정상 수행되었는지 확인
State System에서 정상 수행 여부를 확인 후 실행이 되지 않았다면 Remote Execution을 호출하여 실행
Minion의 /src/salt/states 경로를 Salt State Tree의 Root로 사용
단일 파일 형태 (/src/salt/states/mystate.sls) & 폴더 구성 (/srv/salt/states/mystate/init.sls) 로 구성 및 저장
salt:// 포맷은 State Tress의 파일을 제공하는 Salt File Server를 가리킴
/salt/states/users/init.sls | /salt/states/nginx/init.sls | /salt/state/php-fpm/init.sls | /salt/states/phptest/init.sls 형태로 작성
Salt Runners
Salt Runner
Runner SubSystem은 Salt Master에서 실행되는 Salt Module을 제공함
Runner는 salt-run 명령행 인터페이스를 사용하여 호출됨 (호출은 Master에서 실행하므로 대상에 포함되지 않음)
Runner는 작업 상태 표시, 실시간 이벤트 확인, Salt의 파일 서버 관리, Mine 데이터 확인, Minion에게 Wake-On을 보냄, Web Hook를 호출, 다른 HTTP 요청을 하는 등 다양한 수행을 할 수 있음
salt-run 명령에 인수를 전달하는 문법은 Salt Remote Execution에서 사용하는 문법과 동일
단일성 명령 실행할 때 사용
Salt Orchestrate Runner
Orchestrate Runner는 Salt의 핵심 기능 중 하나인 명령을 실행하고 정의된 순서로 여러 Minion에 구성을 적용하는 기능을 제공하므로 자체 섹션을 가짐
예를 들어 Orchestrate Runner를 사용하면 State System의 모든 기능을 사용하여 여러 시스템을 구성할 수 있음
salt-run은 단일성 명령이지만 여러 Minion에 명령 실행 가능
Salt Data
Master ↔︎ Minion & Minion ↔︎Minion 간의 데이터 이동 관련된 내용
Salt Grains
주요 Host System과 관련하여 Minion이 수집하고 유지하는 정보의 조각 (OS, Memory, Disk, Network Interface등과 같은 시스템 속성을 수집)
일반적으로 Minion의 Agent Daemon에 의해 수집되고 요청시 Master에게 전달됨
Grains는 구성 변경 또는 명령에 대한 인수로 사용될 수 있음 (예를 들어 Grains를 사용하여 구성 파일 변경 또는 명령 인수로 특정 IP 주소를 가져올 수 있음)
Master는 Grains를 Minion에게 할당할 수 있는데 역할을 할당받은 Minion은 Grains를 사용하여 Master의 역할을 할 수 있음
Salt Pillar
Grains를 Master → Minion에 할당하는 것이 가능하지만 대부분의 구성 변수는 Pillar System을 통해 할당됨
Salt에서 Pillar는 Minion이임의로 할당된 데이터를 검색하는데 사용할 수 있는 Key-Value 저장소를 나타냄
이는 조직적 목적으로 중첩되거나 계층화 될 수 있는 사전 데이터 구조로서 기능을 함
Pillar는 값을 할당하기 위해 Grains보다 몇가지 중요한 이점을 제공하는데 가장 중요한 점은 Pillar Data는 할당된 Minion에서만 사용할 수 있다는 것임 (다른 Minion들은 내부에 저장된 값에 접근할 수 없음)
따라서 노드 또는 노드의 하위집합에 대한중요한 데이터를 저장하는데 이상적임 (비밀번호 또는 데이터베이스 연결 문자열은 대부분 Pillar 구성으로 제공됨)
Pillar Data는 종종 구성 데이터를 구성 템플릿에 주입하는 방법으로 구성관리 컨텍스트에서 활동됨
Salt는 구성 파일의 변수 부분을 적용할 노드에 특정한 항목으로 대체하기 위한 템플릿 형식을 제공함 (Grains가 Host Data를 참조할 때 종종 이 방법이 사용)
Salt Mine
Minion에게 정기적으로 실행되는 명령의 결과가 저장될 수 있는 마스터 서버의 영역 (Cron 작업의 결과 저장)
Mine의 목적은 Minion 머신에서 실행되는 임의 명령의 결과를 수집하는 것과 Grains 데이터에 대한 보완재로서 머신의 최신 정보를 제공하는 것
Mine은 가장 최근 결과만 저장함, 즉 기록 데이터에 Access 해야하는 경우 도움이 되지 않음
Minion은 Mine System을 통하여 상대방에 대한 데이터 쿼리를 할 수 있음
Salt Pyton
Salt Module
Salt의 각 SubSystem은 Python의 Module로 구성
Module은 Application (Mysql, Docker), 시스템 구성요소 (디스크, 파일) 를 관리하거나 외부 시스템 (gitfs) 과 상호작용하는 기능 그룹으로 생각할 수 있음
모든 모듈은 Salt Source의 폴더에 있으며 모듈의 확장자는 .py 로 끝남
Module은 Salt Namespace 형식으로 SubSystem.Module로 표기되며 이 Namespace로 SubSystem Module의 유형을 쉽게 알 수 있음
Module에는 필요한 기능이 포함되는데 예를 들어 파일 실행 모듈 (salt.modules.file) 은 파일 관리가 중요하기 때문에 관련된 기능을 많이 가지고 있음, 또한 uwsgi 통계 서버 모듈 (salt.modules.uwsgi) 에는 하나만 있음
Salt Function
Function은 System 내에서 관리 및 구성을 하기 위해 호출할 수 있는 Module내의 특정 명령으로 생각할 수 있음
Ingress는 서비스는 L4 Layer의 Service와 달리 L7 Layer의 서비스이다.
쿠버네티스의 Ingress는 HTTP(S) 기반의 URL Path LoadBalancing을 하는 서비스라고 보면 된다.
아래는 Ingress의 구성도이다.
Ingress는 URL 기반 로드밸런싱을 하며 구동되려면 뒷단에 Service가 있어야 한다.
Ingress -> Pod는 불가능하며 Ingress -> Service -> Pod 형태로 구성이 되어야 한다.
인그레스는 리소스와 컨트롤러로 구성되는데 yaml로 정의하는 것은 리소스이며 실제 트래픽을 처리하도록 하는 것은 컨트롤러가 한다.
아래의 그림을 보자
클라이언트로부터 트래픽이 유입되면 인그레스 컨트롤러가 받아 내용을 확인하고 설정된 인그레스 리소스의 Rule대로 포드에게 트래픽을 전달한다.
위의 그림처럼 구성되는 이유는 Ingress 컨트롤러의 경우 어떤 Pod로 트래픽을 전달해야할지 알지 못한다. 단지 자기와 연동된 인그레스 리소스만 알고 있을뿐이다.
컨트롤러는 자신과 연동된 인그레스 리소스에게 들어온 트래픽에 대한 경로 정보를 요청하고 인그레스 리소스는 자신에게 정의된 Rule 대로 연동된 서비스에게 다시 경로 요청 후 서비스에 등록된 포드의 엔드포인트를 받게되면 컨트롤러가 전달받은 엔드포인트로 트래픽을 전달하는 방식이다.
Yaml로 정의하여 생성한 인그레스 리소스는 Rule을 정의하는 리소스일뿐 실제 트래픽을 전달하는 것은 컨트롤러가 한다는 것이 핵심이다.
온프레미스 기반에서는 직접 컨트롤러를 인그레스 리소스와 연동하여야한다는데 이 부분은 해보지 않아 예제로 만들지는 못하였다.
쿠버네티스에서의 로드밸런싱에는 Service와 Ingress가 있는데 간단하게 Service는 L4 로드밸런서, Ingress는 로드밸런서 이해하면 된다.
우선 Service에 대해 설명하겠다.
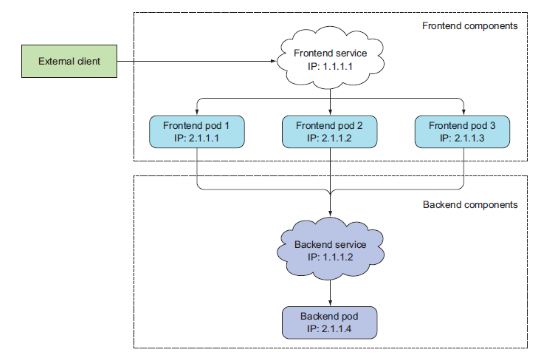
Service는 다른 포드의 요청이나 외부 클라이언트로부터 오는 HTTP 요청에 응답한다. 외부 클라이언트는 L4 로드밸런서를 외부로 노출시켜 트래픽을 받아 서비스에 속한 포드에 전달하는 것인데 다른 포드의 요청이라는 건 이해하기 애매할 수 있다. 이건 간편하게 내부 로드밸런서를 사용하는 경우로 이해해도 좋다. 물론 사용 사례일 뿐이니 각 환경마다 다르다.
외부 클라이언트 -> 외부노출 Service -> Webserver Pod -> 내부 Service -> WasServer Pod
이런식으로도 구성 가능하다.
일단 서비스를 사용하는 일반적으로 로드밸런서를 사용하는 이유와 비슷하지만 쿠버네티스 환경에서는 포드는 Static IP를 가지지 않고 노드 환경에 따라 삭제되고 재생성되는 일이 많으며 포드가 노드로 스케줄되기 전에 IP를 할당받으므로 클라이언트는 서버 포드의 IP를 알 수 가 없다. 이런 문제가 있기 때문에 Service라는 리소스가 필요한 이유이다.
쿠버네티스 서비스란 동일한 서비스 (webserver, api server와 같은) 를 제공하는 포드 그룹에 하나의 진입점을 위해 생성하는 리소스이다. 하나의 진입점이란 IDC 환경에서 L4 스위치를 사용할때 VIP를 사용하여 하단에 리얼 IP를 가진 서버를 묶듯이 이렇게 사용하는 VIP라고 이해하면 될것같다. 서비스가 생성되고 할당한 IP주소와 포트는 서비스가 삭제되기전까지 변하지 않는다.
위의 그림처럼 Service라는 하나의 진입점으로 들어온 트래픽은 하단의 포드 그룹에 로드밸런싱 된다.
Service의 기능중 sessionAffinity라는게 있는데 AWS ELB의 Sticky Session과 같은 기능이라고 보면 된다. ELB에서 Sticky Session을 지정하면 A클라이언트가 A인스턴스로 접속 후 다시 접속을 요청하면 B인스턴스가 아닌 A 인스턴스로 접속할 수 있게 세션을 열어주는 것인데 이것은 https://bcho.tistory.com/tag/sticky%20session 조대협님의 글을 읽어보길 추천한다.
sessionAffinity를 유지할 클라이언트 IP를 지정해야하는데 이유는 아래와 같다.
Sticky Session, 즉 sessionAffinity를 유지하려면 세션이 쿠키 기반의 옵션을 제공해야하는데 이는 HTTP 수준 (L7 Layer) 에서 동작을 해야한다.
하지만 Service는 TCP/UDP 수준의 L4 Layer이다. 그렇기 때문에 패킷을 처리하고 페이로드 (전송되는 데이터) 에 대해서는 신경을 쓰지 않는다.
그렇기때문에 IP를 지정해서 유지해줘야하는 것 (쿠키는 HTTP 프로토콜에서만 의미 있기 때문에 서비스는 쿠키를 처리할 수 없기에 세션이 쿠키 기반 옵션을 제공하지 않는 것) 이다.
이 외에 간단한 예제 몇개를 올려놓겠다.
- 다중 포트 노출
- 이름으로 포트 사용
Service 파일에서 포트에 name 속성을 지정하면 포드에서 포트를 적을 필요없이 http, https 등과 같이 사용할 수 있다.
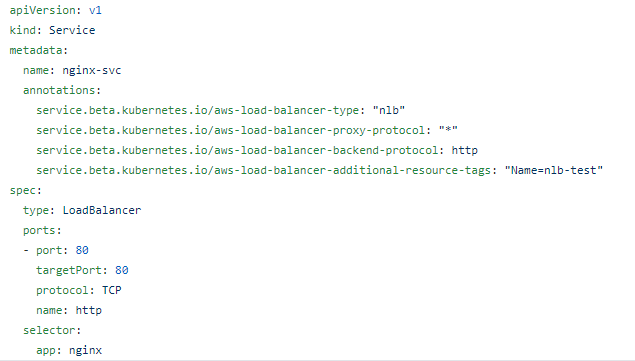
아래는 AWS에서 Service를 생성하면 NLB로 생성되는 예제이다.
이대로 구성하면 바로 NLB가 생성된다. ALB의 경우는 이것보다는 좀 더 복잡하다. 추가되야할게 두가지 더 있다. 이건 Ingress 항목에서 설명하겠다.
서비스의 타입에는 ClusterIP, NodePort, LoadBalancer, External Name 이렇게 네 가지가 존재한다. LoadBalancer는 방금 위에서 설명했고 Nodeport에 대해 설명하겠다.
NodePort는 말 그대로 노드의 포트를 사용하는 것이다. 아래 그림을 확인해보자
우선 외부 클라이언트는 노드의 30123포트를 통해 서비스에 접근하고 서비스에서 포드에게 트래픽이 전달된다.
Service를 생성하면 노드의 포트를 랜덤으로 할당하는데 지정된 노드의 포트를 사용하고 싶으면 이렇게 사용하여도 된다.
여기서 연관된 리소스 중 하나인 엔드포인트에 대해 추가 설명하겠다. 서비스를 생성하고 kubectl describe svc OOO 명령을 실행하여 설명을 보면 Endpoint라는 필드가 존재한다.
서비스는 포드에 직접 링크하지 않는다. 대신 이 엔드포인트라 불리는 리소스가 서비스와 포드 사이에 존재하며 이 서비스를 통해 들어오는 트래픽이 전달될 타겟을 지정한다.
즉 엔드포인트는 서비스에 의해 노출되는 IP주소와 포트의 목록이라 보면 된다.
출력 내용을 보면 포드의 IP와 포트가 엔드포인트로 지정되어 서비스에 등록되어 있다.
이 엔드포인트를 수동으로도 지정할 수 있는데 이런 경우 서비스가 연결을 포워딩할 IP와 포트를 직접 지정하는 경우에 사용된다.
아래는 수동으로 지정된 엔드포인트 매니페스트이다.
- 서비스 리소스
- 엔드포인트 리소스
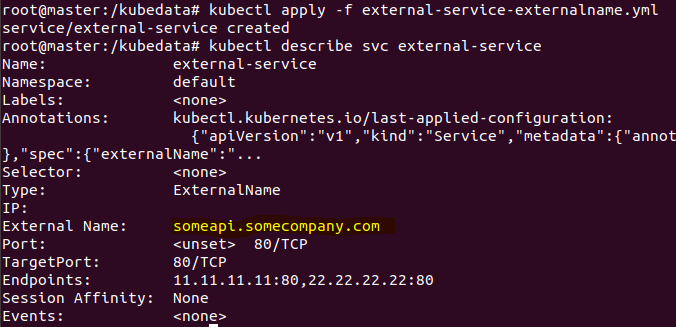
위 방식은 수동으로 서비스와 엔드포인트를 지정한 방식이며 아래처럼 서비스에 ExternalName 형식으로 지정할 수 있다.
위처럼 엔드포인트를 지정하는 서비스는 클러스터 밖에 서비스에 접근하기 위해 사용된다.
여기서 클러스터 밖의 서비스란 AWS RDS와 같이 데이터베이스나 다른 클라우드 서비스를 의미한다. 일반적으로 대부분의 운영 서버들은 DB에 접근하기 때문에 ExternalName 템플릿은
많이 쓰일 것이다.
생성된 서비스를 확인해보면 아래와 같다.
여기서 하나 체크할 부분은 서비스인데도 IP가 없다. 왜 그럴까?
ExternalName 서비스는 기본적으로 DNS레벨에서 구현되며 작동한다. 그러므로 ExternalName 서비스로 연결하는 클라이언트는 서비스 프록시를 통하지 않고 직접 외부서비스로 연결한다.
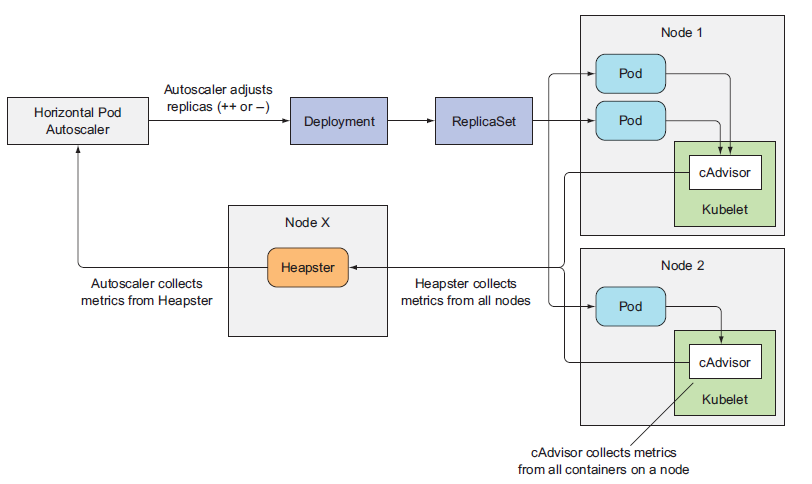
포드의 오토스케일링에 대해서 알아본다. 레플리카셋으로 구성된 포드는 원하는 숫자만큼 포드를 유지시켜주지만 오토스케일링을 할 수 있는 기능은 없다. 그렇기 때문에 포드를 오토스케일링하려면
별도의 포드를 구성해 오토스케일링을 해야한다. 이런 기능을 해주는 것이 HorizontalPodAutoscaler 이다.
오토스케일링하는 방법에는 스케일 업,다운 또는 스케일 인,아웃이 있는데 스케일 업,다운은 VPA (VerticalPodAutoscaler) 라는 기능을 사용하고 스케일 인, 아웃은 HPA (HorizontalPodAutoscaler) 를 사용한다.
지금 알아볼 것은 HPA 이다.
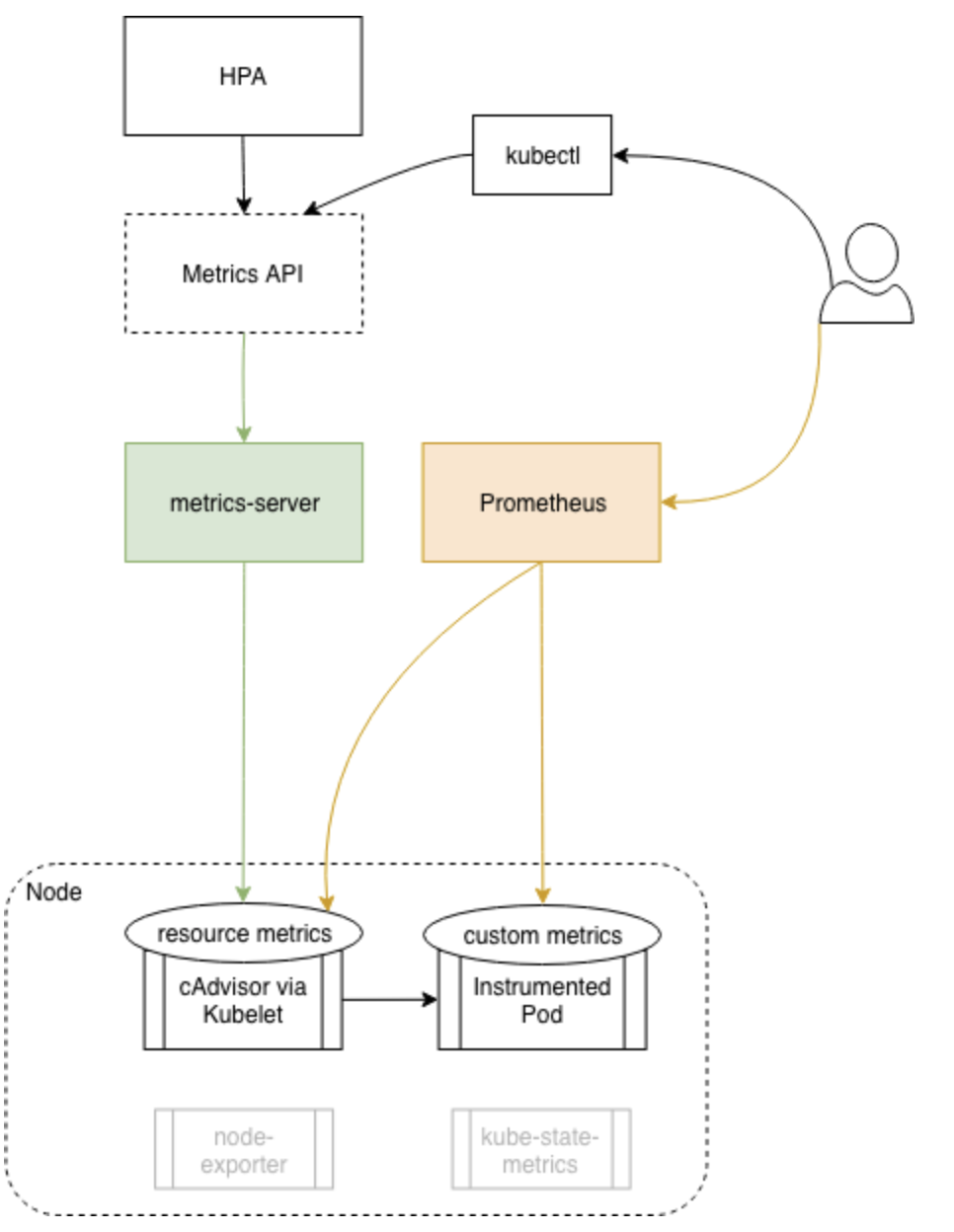
오토스케일링 프로세스
오토스케일링 프로세스는 세 단계로 나눌 수 있다.
1. 스케일된 리소스 객체가 관리하는 모든 포드의 메트릭을 가져옴
2. 지정된 목표 값에 메트릭을 가져오는 데 필요한 포드 수를 계산
3. 스케일된 리소스의 복제본 필드를 업데이트
노드 X 부분은 힙스터로 되어있는데 이제 힙스터는 사용하지 않으니 메트릭서버 또는 프로메테우스를 사용하면 된다.
이렇게 가져온 데이터를 통해 지정된 목표값 (cpu, memory 등) 과 현재 포드 수를 계산해 포드를 늘려야할지 줄여야 할지 결정한다.
가져온 데이터를 계산하여 목표값보다 현재 사용중인 사용량이 많다면 HPA는 Deployment의 유지해야하는 복제수 숫자를 늘린다. 이렇게 Deployment 수정하면 Replicaset은 새로운 포드를 생성해야함을 인지하고 스케줄러에게 새로운 포드를 생성하라고 전달한다. 그러면 스케줄러는 새로운 포드를 생성할 노드를 결정하고 해당 노드의 Kubelet에게 포드를 생성하라고 요청한다. 그러면 Kubelet은 Deployment의 템플릿에 정의된 대로 포드를 생성한다. 여기까지가 포드 오토스케일링이 되는 과정이다.
HPA의 계산 매커니즘
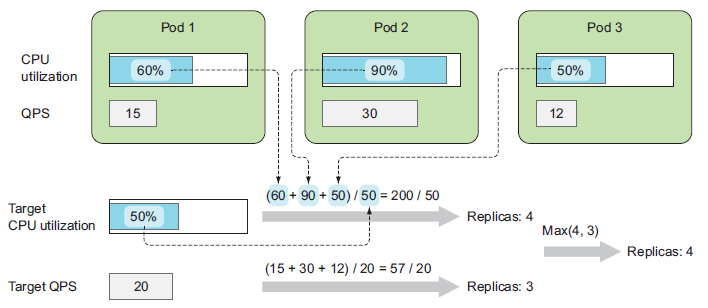
우선 CPU 타켓 기준으로 설명을 하겠다.
현재 세개의 포드가 구동 중이고 오토스케일링을 목표 값은 CPU 50%이다. 50%가 넘으면 스케일 아웃이 되는 설정인 상태
HPA는 메트릭 서버에서 가져온 값을 계산하기 시작한다. 세 포드의 평균 / 목표값 을 계산하여 구동되어야할 Replicas를 결정하는데 여기서 3.6이 나왔다면 HPA는 소수점 반올림으로 4개를 실행해야한다고 결정 내린다. 그렇게 되면 스케일 아웃이되는데 아래에 Target QPS 부분도 확인해보자
위의 그림의 경우 오토스케일링 정책이 2개가 설정되어있는 경우이다. 목표값이 50%가 넘거나 QPS 지표가 목표값을 넘거나 하면 스케일 아웃을 하는 경우이다. 근데 그림을 보면 CPU 지표를 보면 스케일 아웃을 해야하는데 QPS는 현재 상태를 유지해도 되는 지표이다. 이런 경우 어떤 값을 따를까? 가장 높은 값을 목표 값으로 설정한다. 둘중 하나라도 스케일아웃이 필요하면 그 포드는 스케일 아웃된다.
이것만 알아두면 좋을것 같다. 어떤 목표값을 여러개 지정하더라도 그중 하나의 값이 스케일 아웃에 해당된다면 다른 값들은 무시되고 스케일 아웃이 진행된다.
스케일 아웃 계산법을 알아봤으니 스케일인에 대한 계산법도 알아본다.
목표한 값이 50이고 세개의 포드 값이 90이다. 각 포드당 CPU가 30%인경우
그렇게 되면 90/50 = 1.8이 된다. 필요한 포드의 수가 1.8개, 반올림하면 2개
즉 2개의 포드가 필요한 계산이 나오므로 HPA는 실행중인 포드의 수를 2개로 맞추기 위해 하나의 포드를 랜덤으로 삭제하게된다.