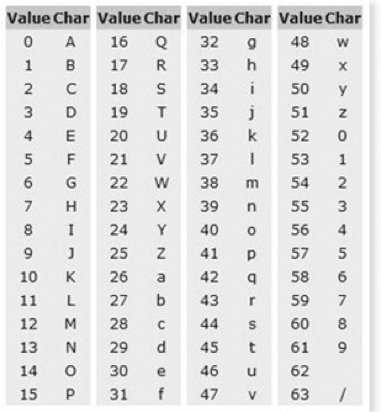
Binary Data를 Text로 바꾸는 Encoding(Binary-to-Text Encoding schemes)의 하나로써 Binary Data를 Character Set에 영향을 받지 않는 공통 ASCII 영역의 문자로만 이루어진 문자열로 바꾸는 Encoding이다.
Base64를 글자 그대로 직역하면 64진법이라는 뜻이다. 64진법은 컴퓨터한테 특별한데 그 이유는 64가 2의 제곱수 64=2^6이며 2의 제곱수에 기반한 진법 중 화면에 표시되는 ASCII 문자들로 표시할 수 있는 가장 큰 진법이기 때문이다.
(ASCII에는 제어문자가 다수 포함되어 있기 때문에 화면에 표시되는 ASCII 문자는 128개가 되지 않는다.)
2020-05-25 13:44:29.123965 N Proxy.cpp:112 predixy listen in 0.0.0.0:7617
2020-05-25 13:44:29.124092 N Proxy.cpp:143 predixy running with Name:PredixyExample Workers:4
2020-05-25 13:44:29.124417 N Handler.cpp:456 h 0 create connection pool for server 192.168.50.15:6380
2020-05-25 13:44:29.124436 N ConnectConnectionPool.cpp:42 h 0 create server connection 192.168.50.15:6380 8
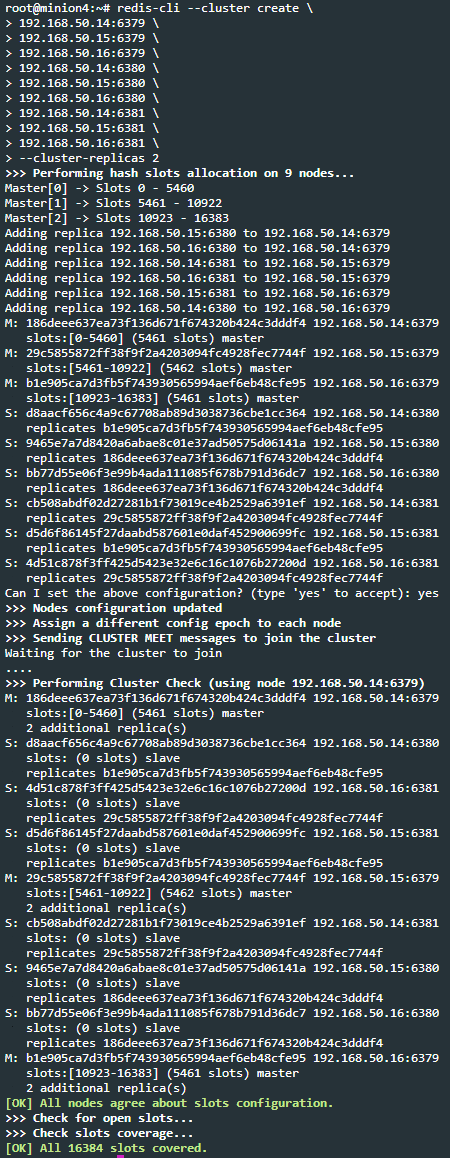
2020-05-25 13:44:29.125279 N ClusterServerPool.cpp:174 redis cluster create new group 29c5855872ff38f9f2a4203094fc4928fec7744f 192.168.50.15:6379@16379 master -
2020-05-25 13:44:29.125298 N ClusterServerPool.cpp:174 redis cluster create new group b1e905ca7d3fb5f743930565994aef6eb48cfe95 192.168.50.16:6379@16379 master -
2020-05-25 13:44:29.125308 N ClusterServerPool.cpp:174 redis cluster create new group 186deee637ea73f136d671f674320b424c3dddf4 192.168.50.14:6379@16379 master -
~~~~~~~~~~~~~~~~~~~~~~~~
Test
1. Client Get Query
# redis-cli -p 7617 -h 192.168.50.13 get hello
"world"
predixy가 실행중인 서버에서 hello key의 world value를 리턴하였다.
만약 predixy가 없는 상황이라면 redis cluster에 직접 질의를 해야하고 보통의 구조에서는 하나의 Master에서 모든 요청을 처리하기때문에 부하가 발생할 수 있다.
2. Log
2020-05-25 13:46:37.252826 N Handler.cpp:456 h 3 create connection pool for server 192.168.50.14:6380
2020-05-25 13:46:37.252874 N ConnectConnectionPool.cpp:42 h 3 create server connection 192.168.50.14:6380 40
2020-05-25 13:46:38.012174 N Handler.cpp:373 h 1 accept c 192.168.50.10:35870 42 assign to h 0
2020-05-25 13:46:38.012860 N Handler.cpp:212 h 0 remove c 192.168.50.10:35870 42 with status 2 End
192.168.50.10에서 온 요청을 redis master 중 요청한 key를 가진 slot이 있는 master (192.168.50.14) 로 전달하였다.
3. redis latency check (predixy support)
# redis-cli -p 7617 -h 192.168.50.13 INFO Latency all
# LatencyMonitor
LatencyMonitorName:all
<= 100 36 3 100.00%
T 12 36 3
# ServerLatencyMonitor
ServerLatencyMonitorName:192.168.50.14:6379 all
ServerLatencyMonitorName:192.168.50.15:6379 all
ServerLatencyMonitorName:192.168.50.16:6379 all
ServerLatencyMonitorName:192.168.50.14:6380 all
ServerLatencyMonitorName:192.168.50.15:6380 all
ServerLatencyMonitorName:192.168.50.16:6380 all
ServerLatencyMonitorName:192.168.50.14:6381 all
ServerLatencyMonitorName:192.168.50.15:6381 all
ServerLatencyMonitorName:192.168.50.16:6381 all
predixy에서 지원하는 기능 중 하나로 각 Redis node에 대한 Latency를 확인할 수 있다.
레디스는 단일 인스턴스만으로도 운영이 가능하지만 물리 머신이 가진 메모리의 한계를 초과하는 데이터를 저장하고 싶거나 failover에 대한 처리를 통해 HA를 보장하려면 센티널이나 클러스터 등의 운영 모드를 선택해서 사용해야 한다.
운영 모드 (Operation Modes)
단일 인스턴스 (Single Instance)
HA를 지원하지 않는다.
센티널 (Sentinel)
HA를 지원하며 Master/Slave Replication 구조를 가진다.
Sentinel Process는 Redis와 별도의 Process로 동작하며 여러개의 독립적인 Sentinel Process들이 협동하여 운영된다 (SPOF 아님)
안정적인 운영을 위해서는 최소 3개 이상의 Sentinel Instance가 필요하며 FailOver를 위해 과반수 이상의 Vote가 필요하다.
Redis Process가 실행되는 각 서버마다 각각 Sentinel Process를 띄어놓거나 Redis에 접근하는 Application Server에 Sentinel Process를 띄어놓고 사용한다. (여러가지 구성이 가능)
지속적으로 Master/Slave가 제대로 동작하는지 모니터링하다가 Master에 문제가 감지되면 자동으로 FailOver를 수행한다.
Application에서 Sentinel에서 Master가 어떤 Instance인지 확인하여 Master 접근하는 방식을 사용한다면 Master 장애로 FailOver시 Application에서도 자동으로 Master 변경이 가능하다.
즉, Application에서 Sentinel에 연결하여 현재 Master를 조회하는 방식이다.
클러스터 (Cluster)
HA와 Sharding을 지원한다. Sentinel과 동시에 사용하는거이 아니라 완전히 별도의 솔루션이다.
DataSet을 자동으로 여러 노드에 나눠서 저장해준다. Redis Cluster 기능을 지원하는 Client를 써야만 Data Access 시에 올바른 노드로 Redirect가 가능하다.
Cluser Node들은 기본설정인 6379 포트를 Data Port로 사용하며 Cluster는 Cluster Bus Port를 사용하여 자체적인 바이너리 프로토콜을 통해 Node to Node 통신을 한다. (보통 Cluster Bus Port는 6379에 10000을 더한 16379 Port를 사용한다.)
이 Cluster Bus Port를 통해 Node 간 Failure Detection, Configuration Update, FailOver Authorization 등을 수행한다.
Sharding은 최대 1000개의 Node로 Sharding해서 사용가능하며 그 이상은 권장하지 않는다. Consistent Hashing을 사용하지 않는 대신 Hash Slot이라는 개념을 도입하여 사용한다.
Hash Slot을 결정하는 방법으로는 CRC16(key) Mod 13684로 CRC16을 이용하면 16384개의 Slot에 균일하게 잘 분배된다.
노드별 자유롭게 Hash Slot을 할당 가능하다.
예를 들면 A Node에 0개부터 5500개, B Node에 5501개부터 11000개, C Node에 11001개부터 16383개를 할당할 수 있다.
운영중단 없이 Hash Slot을 다른 노드로 이동시키는것이 가능하며 노드를 추가하거나 삭제하고 노드별 Hash Slot 할당량을 조절할 수 있다. (노드의 개수에 따라 Slot할당을 다르게 가져갈 수 있다.)
Multiple Key Operations를 수행하려면 모든 키값이 같은 Hash Slot에 들어와야 한다.
이를 보장하기 위해 Hash Tag라는 개념을 도입하여 사용한다. {} 안에 있는 값으로만 Hash 계산을 한다. ({foo}_mykey}, {foo}_your_key})
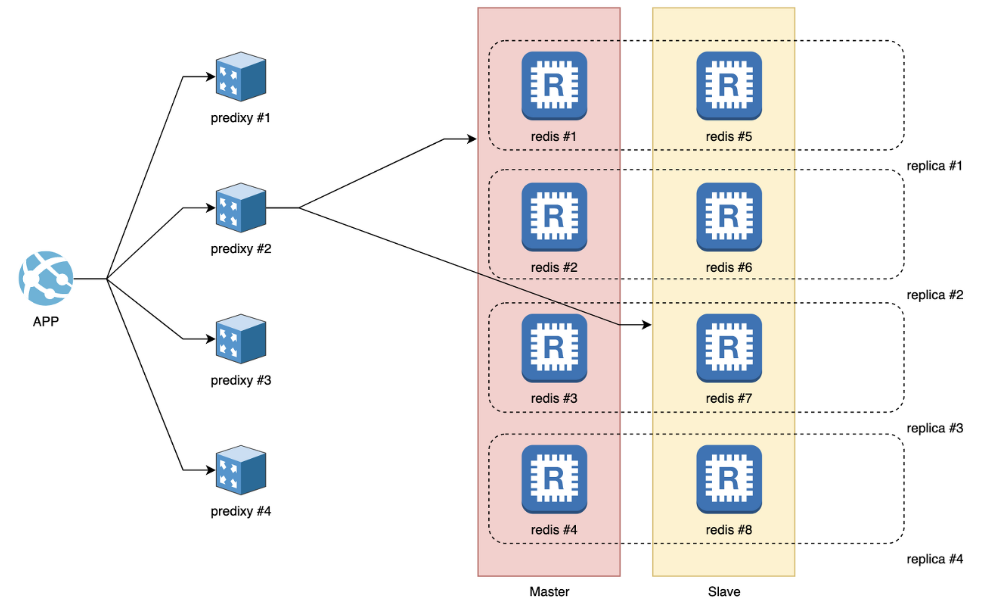
Fail Over를 위해 클러스터의 각 노드를 N대로 구성 가능하다. Master 1대 / Slave Replication (N대) 구성이다.
Async Replication (Master -> Slave Replication 과정에서 Ack를 받지 않는다.) 즉, 데이터를 보내지면 정확히 도착하였는지에 대한 응답을 받지않는 것이다.
그렇기 때문에 데이터 손실 가능성이 존재한다. (Master가 Client 요청을 받아서 Ack를 완료한 후 받은 Client의 요청을 Slave Replication으로 보내기전에 Master가 죽는 경우가 존재한다.)
Redis Client는 Cluster 내의 어떤 노드든 쿼리를 날려도 된다. (Slave에 쿼리를 날리는 것도 가능하다. 예를 들어 GET my_key 와 같은 쿼리)
그렇게 되면 쿼리를 받은 노드가 해당 쿼리를 분석하고 해당 키를 자신이 갖고 있다면 바로 찾아서 리턴하고 그렇지 않은 경우 해당 키를 저장하고 있는 노드의 정보를 리턴한다.
Client는 전달받은 노드의 정보로 다시 쿼리를 보내 요청한 쿼리에 대한 정보를 전달받는다. (리턴은 MOVED 3999 127.0.0.1:6381 형식으로 응답받는데 이 내용으로 다시 쿼리를 보낸다.)
메모리 동작 방식
Key가 만료되거나 삭제되어 Redis가 메모리를 해제하더라도 OS에서 해제된 분량만큼 바로 메모리가 확보되지는 않는다. (꼭 Redis만 해당되는 얘기는 아님)
예를 들어 5GB는 3GB의 데이터를 메모리에서 해제하더라도 여전히 OS 메모리 사용량은 5GB로 잡혀있다.
하지만 다시 Data를 추가하면 Logically Freed된 영역, 즉 해제되었지만 OS에 반환되지 않은 영역에 할당되므로 물리적인 5GB를 넘지는 않는다.
따라서 Peak Memory Usage를 기준으로 Memory를 잡아야한다. 예를 들어 5GB 사용하고 가끔 10GB가 필요한 경우가 있다면 10GB 이상을 가진 머신이 필요한것이다.
MaxMemory 설정을 해두는 것이 좋은데 설정을 하지 않으면 Memory를 무한히 사용하다가 OOM이나 머신에 장애가 발생할 가능성이 높아진다.
MaxMemory 설정시의 Eviction Policy (Memory 해제 정책) 는 아래와 같다.
No-Eviction : 추가 Memory를 사용하는 Write Command에 대해 Error를 리턴
Allkeys-LRU : 전체 아이템 중에서 LRU (페이지 교체 알고리즘으로 가장 마지막에 사용된 페이지를 새로운 페이지로 교체하는 방식)
Volatile-LRU : Expire 되는 아이템 중에서 LRU
Volatile-TTL : Expire 되는 아이템 중 TTL이 얼마 안남은 순으로 교체
RDB Persistence를 사용한다면 MaxMemory를 실제 가용 Memory의 45% 수준으로 설정하는 것을 권장한다. Snapshot을 찍을때 현재 사용중인 Memory 양만큼 필요하기 때문이다. (5%는 오버헤드에 대비하기 위해 여유분)
만약 RDB Persistence를 사용중이지 않다면 95%정도로 사용하여도 된다.
동일 Key-Value Data를 저장한다고 가정했을 때 Cluster Mode를 사용할 경우 Single Instance 보다 1.5 ~ 2배 정도 Memory를 더 사용하는 것에 주의해야 한다.
Redis Cluster의 경우 내부적으로 Cluster안에 저장된 Key를 Hash Slot으로 Mapping하기 위한 Table을 가지고 있기 때문에 추가적인 Memory OverHead가 발생한다.
이 때문에 Key의 숫자가 많아질수록 Memory OverHead가 더 빈번히 발생한다. 4버전 부터는 이전 버전보다 Memory 최적화 기능이 포함되어 Memory를 더 적게 사용하지만 여전히 Single Instance보다 많은 Memory를 필요로 한다.
주요 특수 기능
다양한 데이터 구조 지원
단순히 Key - Value 문자열만 저장하는 것이 아니라 고수준의 데이터 구조를 사용가능 하다.
Ex) Hash, Set, List, SortedSet, ETC
Hash에는 HSET(key, fileds, value), HGET(key,filed)가 있다.
Web Application에서 특정 유저 ID를 Key로 두고 해당 유저의 세부 정보 (Name, Email 등)를 filed로 둔다.
이렇게 하면 특정 유저와 관련된 정보들을 한번에 삭제하는 등 하나의 Namespace처럼 사용할 수있다.
Hash Key당 1000개 정도의 field까지는 Redis가 zipmap을 이용해 압축해서 저장한다. 즉, 1000개의 Key에 저장될 내용이 하나의 Key에 1000개의 field로 저장되는 것이다.
하지만 CPU 사용량이 증가하므로 Application 특성에 맞게 적정 갯수를 잘 선택해야 한다.
- 기존 RabbitMQ와 같은 다른 메시지큐와의 성능차이(훨씬 빠르게 처리)가 나며 그 외에도 클러스터 구성, Fail-Over, Replication과 같은 여러가지 특징을 가짐
- 아파치 카프카는 분산 스트리밍 플랫폼이며 데이터 파이프라인을 만들때 주로 사용
- 대용량의 실시간 로그처리에 특화되어 있는 솔루션이며 데이터를 유실없이 안전하게 전달하는 것이 주목적인 메세지 시스템에서 Fault-Tolerant한 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리할 수 있음
아키텍처
1. Producer가 데이터를 카프카에 적재
2. Foo와 Bar는 각각 3개의 파티션으로 나뉘어져 있고 이 각각의 파티션들은 3개의 복제본으로 복제
3. 3개의 복제본 중에는 하나의 리더(하늘색)가 선출되게 되고 이 리더가 모든 데이터의 읽기/쓰기 연산을 담당
4. 카프카 클러스터에서 데이터를 가져오게 될 때는 컨슈머 그룹 단위로 가져옴
(이 컨슈머 그룹은 자신이 가져와야하는 토픽 안의 파티션의 데이터를 Pull 하게 되고 각각 컨슈머 그룹안의 컨슈머들이 파티션이 나뉘어져 있는 만큼 데이터를 처리)
5. 저장된 데이터를 Consumer Group A와 B가 각각 자신이 처리해야할 Topic을 가져옴
- 파티션들은 운영 도중 그 수를 늘릴 수 있지만 절대 줄일 수 없음 (파티션을 늘리는 것은 신중하게 고려)
용어
- 프로듀서 (Producer)
데이터를 발생시키고 카프카 클러스터에 적재하는 프로세스
메시지 송신 API
특정 Topic에 해당하는 메시지를 생성하는 프로세스, 메시지를 Broker에 전달 (발행/Publish)
Producers는 데이터를 그들이 선택한 Topic으로 Publish
Producers가 메시지를 실제로 어떤 Partition으로 전송할지는 사용자가 구현한 Partition 분배 알고리즘에 의해 결정
(예를 들어 Round-Robin 방식의 Partition 분배 알고리즘을 구현하여 각 Partition에 메시지를 균등하게 분배하도록 하거나, 메시지의 키를 활용하여 알파벳 A로 시작하는 키를 가진 메시지에 P0에만 전송하고, B로 시작하는 키를 가진 메시지는 P1에만 전송하는 형태로 구성도 가능)
- 카프카 클러스터 (Kafka Cluster) : 카프카 서버로 이루어진 클러스터
브로커 (Broker)
카프카 서버
Topic을 기준으로 메시지 관리
Broker는 클러스터로 구성 (이에 대한 분산처리는 Zookeeper가 처리)
Producers와 Consumer가 만날 수 있도록 메시지를 관리하는 서버 클러스터로 Producer에게서 전달받은 메시지를 Topic별로 분류
여러대의 Broker Cluster로 구성 가능하며, Zookeeper에 의해 각 노드가 모니터링
주키퍼 (Zookeeper)
분산 코디네이션 시스템으로 카프카 브로커를 하나의 클러스터로 코디네이팅하는 역활을 하며 카프카 클러스터의 리더를 발탁하는 방식도 주키퍼가 제공하는 기능을 이용
토픽 (Topic)
카프카 클러스터에 데이터를 관리할 시 그 기준이 되는 개념, 토픽은 카프카 클러스터에서 여러개 만들 수 있으며 하나의 토픽은 1개 이상의 파티션으로 구성 (어떤 데이터를 관리하는 하나의 그룹 개념으로 생각하면 됨)
발행(Publish)된 메시지들의 카테코리
유사한 메시지들의 집합으로 Producer는 메시지를 전달한 Topic을 반드시 지정해야함
Partition 단위로 클러스터 각 서버들에 분산 저장
각 Partition은 0부터 1씩 증가하는 offset 값을 메시지에 부여 (Partition내 메시지 식별)
클러스터 내 메시지들은 설정된 기간동안 유지 후 삭제
파티션 (Partition)
각 토픽 당 데이터를 분산 처리하는 단위, 카프카에서는 토픽안에 파티션을 나누어 그 수대로 데이터를 분산처리함 (카프카 옵션에서 지정한 Replica의 수만큼 파티션이 각 서버들에게 복제)
로드밸런싱을 목적으로 Topic을 분할하는 것을 의미
리더, 팔로워 (Leader, Follower)
카프카에서는 각 파티션당 복제된 파티션 중에서 하나의 리더가 선출, 이 리더는 모든 읽기/쓰기 연산을 담당, 리더를 제외한 나머지는 팔로워가 되고 이팔로워들은 단순히 리더의 데이터를 복사하는 역활만 수행
로그 (Log)
Producers가 생성한 메시지
리플리케이션 (Replication)
Fault Tolerance 위해 Partition 단위로 복제
- 컨슈머 그룹 (Consumer Group)
컨슈머의 집합을 구성하는 단위, 카프카에서는 컨슈머 그룹으로서 데이터를 처리하며 컨슈머 그룹안의 컨슈머 수만큼 파티션의 데이터를 분산처리하게 됨
메시지 수신 API
Broker에게서 구독(Subscribe)하는 Topic의 메시지를 가져와 사용(처리)하는 프로세스
Topic에 할당된 쓰레드 개수만큼 쓰레드가 만들어지면 Partition으로부터 메시지를 읽음
하나의 쓰레드는 1개 이상 Partition으로 부터 메시지를 읽을 수 있음
Public void run 메소드 내에 while(is.hasNext())에서 블록킹 되어 있다가 Partition으로 메시지가 들어오면 이 곳에서 메시지를 읽음, 따라서 다른 타겟으로 메시지를 처리하는데 적합한 장소
(메시지를 파일로 저장하던지 대용량 입력이 가능한 하둡이나 NoSQL로 저장하기에 유용)
- 컨슈머 API (Consumer API)
컨슈머에 두 가지 API 제공 (Simple Consumer API, High-Level Comsumer API)
세부적인 것들은 모두 추상화되어 있어 몇 번의 간단한 함수 호출로 Consumer를 구현할 수 있는 High-Level Consumer API
offset과 같은 세부적인 부분까지 다룰 수 있지만 이 때문에 구현하기가 상당히 까다로운 Simple Consumer API가 제공
카프카 파티션 읽기, 쓰기
- 카프카에서 읽기/쓰기 연산은 카프카 클러스터 내의 리더 파티션들에게만 적용
- 하늘색으로 칠해진 각 파티션들은 리더 파티션이며 이 파티션들에게 프로듀서가 쓰기 연산을 진행
- 리더 파티션에 쓰기가 진행되고 난 후 업데이트된 데이터는 각 파티션들의 복제본들에게 복사
- 카프카는 데이터를 순차적으로 디스크에 저장
- 프로듀서는 순차적으로 저장된 데이터 뒤에 붙이는 Append 형식으로 Write 연산을 진행
- 이때 파티션들은 각각의 데이터들의 순차적인 집합인 오프셋(offset)으로 구성
- 컨슈머 그룹의 각 컨슈머들은 파티션의 오프셋을 기준으로 데이터를 순차적으로 처리하게 됨
- 중요한 것은 컨슈머들은 컨슈머 그룹으로 나뉘어서 데이터를 분산 처리하게 되고 같은 컨슈머 그룹 내에 있는 컨슈머 끼리 같은 파티션의 데이터를 처리할 수 없음
- 파티션에 저장되어 있는 데이터들은 순차적으로 데이터가 저장되어 있으며 이 데이터들은 설정값에 따라 데이터를 디스크에 보관 (기본 7일)
- 컨슈머 그룹단위로 그룹 내 컨슈머들이 각각 파티션의 데이터를 처리하는 모습을 나타낸 것으로 만일 컨슈머와 파티션의 개수가 같다면 컨슈머는 각 파티션을 1:1로 맡게 됨
- 만일 컨슈머 그룹안의 컨슈머의 개수가 파티션의 개수보다 적을 경우 컨슈머 중 하나가 남는 파티션의 데이터를 처리
(컨슈머 개수가 파티션의 개수보다 많을 경우 컨슈머는 파티션의 개수가 많을때까지 대기)
사용 예제
Why Use It? 왜 사용하나요?
- High-throughput message capacity
쉽게 이야기해서 단 시간 내에 엄청난 양의 데이터를 컨슈머 쪽으로 전달 가능합니다. 다른 경쟁 제품에 비해 많은 양의 데이터 전송이 가능한 이유는 크게 두 가지 있는데 우선 첫째, 기존의 메세지 시스템이 메세지 브로커 쪽에서 가지고 있던 모든 복잡한 과정 또는 연산들을 제거했고 둘째, 하나의 토픽에 대해 여러 개의 파티션으로 분할 할 수 있도록 해서 컨슈머 쪽에서 분산 처리할 수 있도록 하였습니다. 좀더 자세히 설명하자면 기존의 메세지 시스템들은 (RabbitMQ 같은) 각각의 토픽에 대해 컨슈머들의 인덱스 (데이터를 어디까지 전송받았는지를 알려주는) 정보를 메세지 브로커 쪽에서 관리하였는데 카프카는 이 부분을 컨슈머 쪽으로 책임을 옮겼으며 또한 메세지를 유지하는 방법도 메모리에 잠시 보관하였다가 컨슈머에 전송된 후 삭제하는 방법이 아니라 일반 파일에 Log 형식으로 (데이터가 날짜순으로 저장되고 Append만 가능한 형식) 관리하여 전송 후에 Delete 연산이 필요없는 방식을 사용하고 있습니다. 또한 토픽의 분할 기능을 제공하여 같은 토픽에 대해 여러 개의 컨슈머가 동시에 메세지를 전송 받는 등의 분산 처리를 지원하여 많은 양의 데이터 전송을 가능하게 하고 있습니다.
- Scalability와 Fault tolerant
카프카는 클러스터 모드를 지원하고 있으며 위에 언급했던 토픽 파티셔닝 (하나의 토픽을 여러 개의 파티션으로 나눌 수 있는 기능)과 파티션 복제 (Replication) 기능을 통해 확장성과 Fault tolerant (부분적으로 고장나더라도 중요한 기능들은 정상적으로 작동하는 특성)을 제공하고 있습니다.
- 메세징 시스템 외에 다양한 용도로 사용 가능
일반적인 메세징 시스템과 달리 카프카는 다양한 용도로 사용 가능하며 자세한 사용 용도에 대해서는 아래의 글을 참조하세요.
Use Cases (카프카의 사용 용도의 예)
- Messaging System: 가장 일반적으로 많이 사용되고 있는 용도로 메세지 제공자 (Producer 또는 Source)와 수신자 (Consumer 또는 Sink) 사이에서 메세지를 전달해주는 역할을 합니다. 각각의 컨슈머 (또는 컨슈머 그룹)는 전달받기를 원하는 메세지의 토픽에 구독 신청해야 하며 하나의 토픽에 여러 컨슈머가 구독 신청 할 수 있습니다. (이 경우에 메세지는 구독신청한 모든 컨슈머한테 Broadcast 됩니다.)
- Website Activity Checking 및 Monitoring: 링크드인에서 처음 만들고 사용했던 목적처럼 웹사이트가 정상적으로 돌아가는지 또는 웹사이트 사용 시 유저들의 패턴이 어떻게 되는지 모니터링 또는 웹사이트 이벤트 체킹의 목적으로도 사용 가능하며 (중간에서 메세지를 전달하는 중간자의 역할을 할 수도 있지만 메세지 자체가 디스크에 일정 기간 동안 로깅이 되어 있기 때문에 직접 분석도 가능합니다.)
- Log Aggregation: 하나의 웹사이트가 여러 대의 서버로 운영되고 있다면 (대부분의 엔터프라이즈 웹사이트들이 그렇듯이) 각각의 서버에 있는 로그를 통합해주는 시스템 구축에도 사용 가능합니다.
- Stream Processing & Batch Processing: 요즘 빅데이터 쪽에서 가장 핫한 Spark나 Storm같은 Stream Processing (스트림 처리)을 지원하는 플랫폼이나 Hadoop과 같이 Batch Processing (일괄 처리)을 지원하는 플랫폼과 연결햐여 메세지의 변환도 가능합니다.
- Etc: 그 외에 연결된 DB나 서치 엔진의 일시적 서비스 장애 때문에 다운이 되었을 때 메세지들을 잠시 저장해줄 수 있는 임시 버퍼의 역할도 가능하며 Operational metrics (각각의 토픽에 대해 들어오는 메세지의 수를 정기적으로 체크하여 그 수가 너무 낮거나 높을 때 문제가 있는 확인차 운영팀에 메일등을 통해 알려주는 용도)나 Event sourcing (특정 이벤트들을 시간 순으로 기록하여 나중에 필요할 때 사용하는 용도) 등의 용도로도 사용되고 있습니다.