Kubernetes Ingress
Ingress는 서비스는 L4 Layer의 Service와 달리 L7 Layer의 서비스이다.
쿠버네티스의 Ingress는 HTTP(S) 기반의 URL Path LoadBalancing을 하는 서비스라고 보면 된다.
아래는 Ingress의 구성도이다.

Ingress는 URL 기반 로드밸런싱을 하며 구동되려면 뒷단에 Service가 있어야 한다.
Ingress -> Pod는 불가능하며 Ingress -> Service -> Pod 형태로 구성이 되어야 한다.
인그레스는 리소스와 컨트롤러로 구성되는데 yaml로 정의하는 것은 리소스이며 실제 트래픽을 처리하도록 하는 것은 컨트롤러가 한다.
아래의 그림을 보자
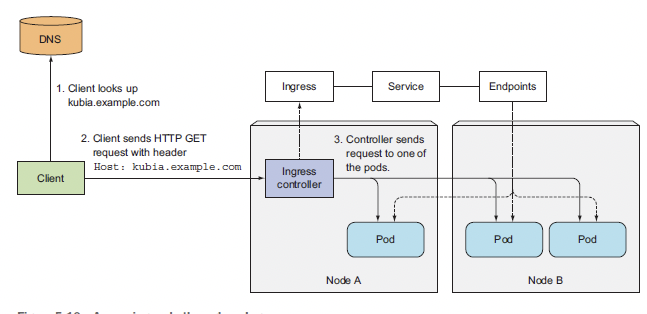
클라이언트로부터 트래픽이 유입되면 인그레스 컨트롤러가 받아 내용을 확인하고 설정된 인그레스 리소스의 Rule대로 포드에게 트래픽을 전달한다.
위의 그림처럼 구성되는 이유는 Ingress 컨트롤러의 경우 어떤 Pod로 트래픽을 전달해야할지 알지 못한다. 단지 자기와 연동된 인그레스 리소스만 알고 있을뿐이다.
컨트롤러는 자신과 연동된 인그레스 리소스에게 들어온 트래픽에 대한 경로 정보를 요청하고 인그레스 리소스는 자신에게 정의된 Rule 대로 연동된 서비스에게 다시 경로 요청 후 서비스에 등록된 포드의 엔드포인트를 받게되면 컨트롤러가 전달받은 엔드포인트로 트래픽을 전달하는 방식이다.
Yaml로 정의하여 생성한 인그레스 리소스는 Rule을 정의하는 리소스일뿐 실제 트래픽을 전달하는 것은 컨트롤러가 한다는 것이 핵심이다.
온프레미스 기반에서는 직접 컨트롤러를 인그레스 리소스와 연동하여야한다는데 이 부분은 해보지 않아 예제로 만들지는 못하였다.
아래의 예제는 직접 생성해본 AWS 에서의 ALB 생성 YAML이다.
1. AWS ALB Controller 생성
- alb-ingress-controller.yaml
# Application Load Balancer (ALB) Ingress Controller Deployment Manifest.
# This manifest details sensible defaults for deploying an ALB Ingress Controller.
# GitHub: https://github.com/kubernetes-sigs/aws-alb-ingress-controller
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
name: alb-ingress-controller
# Namespace the ALB Ingress Controller should run in. Does not impact which
# namespaces it's able to resolve ingress resource for. For limiting ingress
# namespace scope, see --watch-namespace.
namespace: kube-system
spec:
selector:
matchLabels:
app.kubernetes.io/name: alb-ingress-controller
template:
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
spec:
containers:
- name: alb-ingress-controller
args:
# Limit the namespace where this ALB Ingress Controller deployment will
# resolve ingress resources. If left commented, all namespaces are used.
# - --watch-namespace=your-k8s-namespace
# Setting the ingress-class flag below ensures that only ingress resources with the
# annotation kubernetes.io/ingress.class: "alb" are respected by the controller. You may
# choose any class you'd like for this controller to respect.
- --ingress-class=alb
# REQUIRED
# Name of your cluster. Used when naming resources created
# by the ALB Ingress Controller, providing distinction between
# clusters.
- --cluster-name=eks-test
# AWS VPC ID this ingress controller will use to create AWS resources.
# If unspecified, it will be discovered from ec2metadata.
- --aws-vpc-id=vpc-OOOOOO
# AWS region this ingress controller will operate in.
# If unspecified, it will be discovered from ec2metadata.
# List of regions: http://docs.aws.amazon.com/general/latest/gr/rande.html#vpc_region
- --aws-region=ap-northest-2
# Enables logging on all outbound requests sent to the AWS API.
# If logging is desired, set to true.
# - ---aws-api-debug
# Maximum number of times to retry the aws calls.
# defaults to 10.
- --aws-max-retries=10
# env:
# AWS key id for authenticating with the AWS API.
# This is only here for examples. It's recommended you instead use
# a project like kube2iam for granting access.
#- name: AWS_ACCESS_KEY_ID
# value: KEYVALUE
# AWS key secret for authenticating with the AWS API.
# This is only here for examples. It's recommended you instead use
# a project like kube2iam for granting access.
#- name: AWS_SECRET_ACCESS_KEY
# value: SECRETVALUE
# Repository location of the ALB Ingress Controller.
image: docker.io/amazon/aws-alb-ingress-controller:v1.1.2
serviceAccountName: alb-ingress-controller
2. AWS ALB Controller에 대한 Cluster Role 생성 및 바인딩 (Cluster에서 Controller에 대한 권한을 허용해야함)
- alb-ingress-rbac.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
name: alb-ingress-controller
rules:
- apiGroups:
- ""
- extensions
resources:
- configmaps
- endpoints
- events
- ingresses
- ingresses/status
- services
verbs:
- create
- get
- list
- update
- watch
- patch
- apiGroups:
- ""
- extensions
resources:
- nodes
- pods
- secrets
- services
- namespaces
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
name: alb-ingress-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: alb-ingress-controller
subjects:
- kind: ServiceAccount
name: alb-ingress-controller
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/name: alb-ingress-controller
name: alb-ingress-controller
namespace: kube-system
...
3. ALB 생성
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: api-alb-ingress
namespace: api
labels:
app: nodejs
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
#alb.ingress.kubernetes.io/security-groups: sg-OOOOOO
alb.ingress.kubernetes.io/subnets: subnet-aaaaaa,subnet-bbbbbbb
#alb.ingress.kubernetes.io/tags: "Name=alb-test"
#alb.ingress.kubernetes.io/healthcheck-interval-seconds: '30'
#alb.ingress.kubernetes.io/healthcheck-timeout-seconds: '10'
#alb.ingress.kubernetes.io/healthy-threshold-count: '3'
#alb.ingress.kubernetes.io/unhealthy-threshold-count: '3'
alb.ingress.kubernetes.io/healthcheck-path: '/'
#alb.ingress.kubernetes.io/healthcheck-port : '80'
#alb.ingress.kubernetes.io/healthcheck-protocol : HTTP
alb.ingress.kubernetes.io/success-codes : '200'
spec:
backend:
serviceName: api-svc
servicePort: 80
4. ALB 인그레스와 연동된 Service 생성
apiVersion: v1
kind: Service
metadata:
name: api-svc
namespace: api
labels:
app: nodejs
spec:
type: NodePort
selector:
app: nodejs
ports:
- port: 80
targetPort: 80
LoadBalancer는 Ingress가 하기 때문에 Service의 Type은 NodePort가 된다.
'Kubernetes' 카테고리의 다른 글
| Kubernetes Service (0) | 2019.09.17 |
|---|---|
| Kubernetes Monitoring - Version1 (0) | 2019.09.17 |
| Kubernetes HorizontalPodAutoscaler (0) | 2019.08.31 |
| Kubernetes Pod DaemonSet (0) | 2019.08.30 |
| Kubernetes Pod Replica (0) | 2019.08.30 |