728x90
반응형
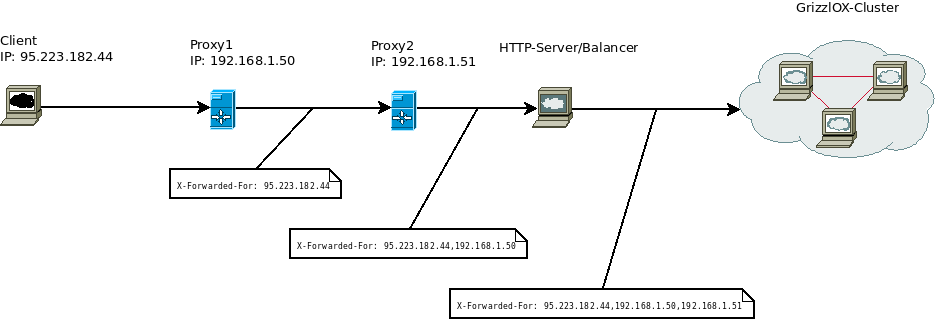
기본 구성도

구성도 설명
- 두 개의 AZ에 하나의 VPC로 4개 Subnet 구성 (Public 망 2개 / Private 망 2개)
- Public Subnet은 IGW를 통해 외부와 통신 (VPC 하나에 한개의 IGW만 Attach 가능)
- Public Subnet은 Public Route Table을 통해 외부와 통신 (Route Table을 생성 후 assign)
- Private Subnet과 Public Subnet은 Private Route Table을 통해 통신 (Route Table을 생성 후 assign)
- Network ACL을 통해 Public, Private Subnet의 보안 정책 구성 (Network ACL은 Subnet 단위로 적용 가능)
- Security Group을 통해 Instance에 대한 보안 정책 구성 (Security Group은 Instance 단위로 적용 가능)
용어 설명
Subnet
- IP 서브넷과 같은 개념으로 하나의 AZ에 속해야 한다.
- VPC 내부에 다수의 Subnet을 생성하여 각각의 AZ에 분산 배치하면 하나의 VPC에 Multi AZ를 사용하도록 디자인 가능
Internet Gateway
- Subnet이 외부와 통신이 되도록 Gateway 설정
- 하나의 VPC에는 하나의 IGW만 Attach 가능
Route Table
- 외부 통신을 위한 Public Subnet의 모든 트래픽이 IGW로 가도록 설정
- Subnet Routing 경로 설정
Network ACL
- 온프레미스의 방화벽과 같은 개념으로 VPC로 유입되는 모든 트래픽을 제어할 수 있음
- VPC의 Network ACL은 Subnet 단위로 적용 가능
- 초기 ACL설정은 All Deny정책으로 별도의 정책을 구성하지 않으면 모든 Subnet 통신은 두절
- ACL은 여러 Subnet에 적용가능하지만 Subnet은 하나의 ACL만 연결 가능
- ACL 규칙은 번호가 낮은 것부터 우선 적용
- VPC당 최대 200개의 ACL 구성 가능
- ACL당 inbound 20개, outbound 20개 까지만 지정 가능
- ACL은 stateless
- AWS에서 권장하는 ACL 규칙 : https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/vpc-recommended-nacl-rules.html
- ACL로 inbound, outbound 규칙 구성 시 Ephemeral Port에 대한 허용 규칙을 신경써주어야 함
- Ex) ACL의 inbound 규칙 80을 허용하게 된다면 80 포트로 트래픽이 들어오는데 이에 대한 응답의 경우 outbound 규칙을 따르게 된다. 만약 outbound 규칙에서 응답 포트를 구성하지 않는다면 ACL에 의해 deny되므로 client에게 요청 결과가 전송되지 않는 현상이 발생
Stateless
- 트래픽에 대한 상태를 저장하지 않는다는 의미로 요청과 응답은 트래픽의 상태와 상관없이 각각 inbound와 outbound 규칙을 따른다는 것
Ephemeral Port
- TCP Connection 시에 Kernel이 임의로 port를 binding 하는 경우가 있는데 이런 Port를 Ephemeral Port라고 함
- AWS에서 제공하는 AWS Linux AMI인 경우 Ephemeral Port Range가 32768 - 60999로 설정
- # cat /proc/sys/net/ipv4/ip_local_port_range 명령으로 확인 가능
Security Group
- Instance에 대한 inbound, outbound 트래픽을 제어하는 방화벽 역활
- Network ACL의 경우 Network 레벨의 방화벽이라면 Security Group은 Instance 레벨의 방화벽
- Security Group은 Instance 단위로 적용 가능
- 동일한 Subnet 내에서 통신일 경우 ACL 규칙과 상관없이 Security Group의 규칙을 적용 받음
- Security Group의 규칙은 Allow 지정 방식이며 Deny 지정은 불가능
- 기본적으로 inbound 트래픽의 경우 All Deny
- Outbound 트래픽의 경우 기본적으로 All Allow 상태이며 All Allow 규칙은 삭제가 가능하고 원하는 Allow 규칙만 설정 가능
- Security Group은 Stateful 하기 때문에 허용된 inbound 트래픽에 대한 응답은 outbound 규칙에 관계없이 허용
- Network ACL과는 다르게 State를 기억하기때문에 outbound나 Ephemeral Port에 대한 고민을 하지 않아도 됨
Flow Log
- VPC 내 트래픽에 대한 로그 정보를 수집하는 기능
- Instance에게 유입되는 트래픽을 모니터링할 수 있으므로 보안을 위한 추가도구로 사용 가능
- Network ACL로 인한 통신 두절 상황에서 트러블 슈팅 도구로 사용 가능
- Flow Log를 설정하면 로깅 데이터는 CloudWatch Log를 사용하여 저장
참조 URL : https://bluese05.tistory.com/47
반응형
'AWS' 카테고리의 다른 글
| AWS CodeCommit (0) | 2019.04.09 |
|---|---|
| AWS CodePipeline (0) | 2019.04.09 |
| AWS Auto Scaling (0) | 2019.03.08 |
| AWS Bastion Host (0) | 2019.03.08 |
| AWS CloudFront(CDN) (0) | 2019.03.08 |





.png)

.png)

.png)